Why Sigma: AI evaluation for real-world deployments

AI is advancing fast. Evaluation is not. Most AI systems today are still evaluated the way they were a few years ago — with automated benchmarks and internal QA processes designed for predictable outputs. But AI is no longer predictable. It is conversational, multimodal, multilingual, and increasingly agentic. It doesn’t just return answers. It interacts, […]
Why better data builds better AI
The role of data in teaching nuanced AI Generative AI doesn’t just need labeled data; it needs representative data. That means multilingual, multi-domain corpora designed to teach tone, sentiment, and context — not just keywords. Sigma’s multilingual, multitask corpus spans over 300,000 human-reviewed texts across 10 languages and seven NLP tasks, from sentiment analysis to […]
Teaching AI to truly understand what we mean
Why meaning matters for AI LLMs trained only on raw text often produce plausible but incorrect interpretations. The result: outputs that sound convincing but fail to reflect reality. When AI misses tone, emphasis, or structure, it can frustrate users, or worse, cause harm. Imagine a voice assistant that fails to distinguish between a polite suggestion […]
Why red-teaming your AI protects your brand and your users
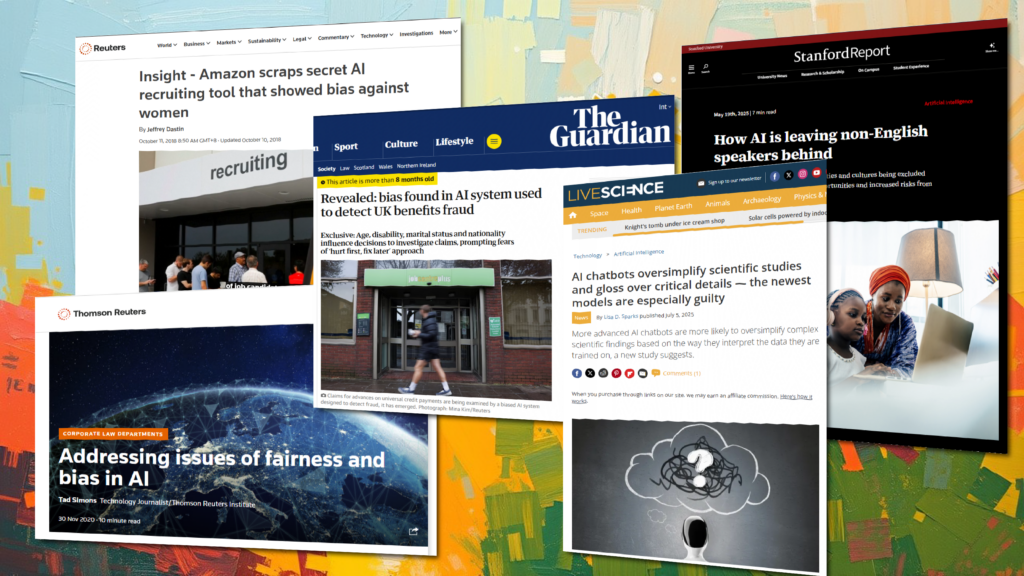
Why traditional testing isn’t enough Most organizations validate AI systems with internal QA or benchmark datasets, but these don’t simulate adversarial conditions. Real users (or bad actors) may try prompts that testers never imagined — seeking confidential data, bypassing safety filters, or eliciting unethical instructions. Recent headlines show what happens when these safeguards aren’t in […]
Connecting the dots: why integration annotation powers better AI
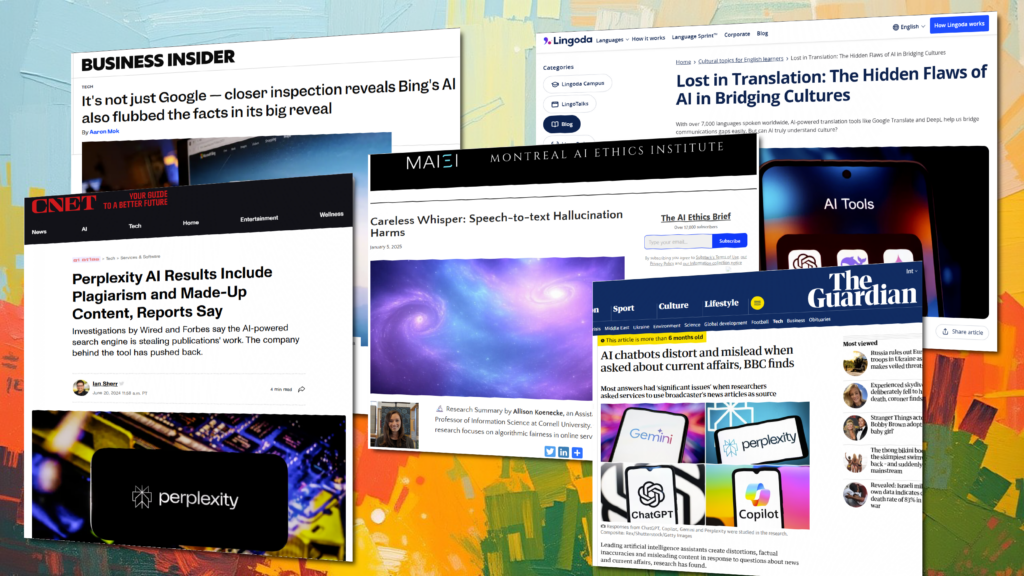
Why multimodal matters Generative and agentic AI are moving beyond single prompts to multi-step scenarios. For example: Without integration, these systems return fragmented responses — and that leads to problems. Real-world examples highlight the risks: These cases show why cross-channel annotation is not optional; it’s foundational. How Sigma’s Integration workflows connect channels Sigma’s Integration service […]
Teaching AI to hear what we mean, not just what we say

When accuracy isn’t enough When a customer hears, “I’m happy to help,” they instantly know if the speaker truly means it — by tone, pacing, and emphasis. AI, however, often misses those cues. Large language models (LLMs) and voice systems may produce technically correct responses that land as emotionally tone-deaf, culturally inappropriate, or misaligned with […]
When accuracy isn’t enough: building truth into generative AI

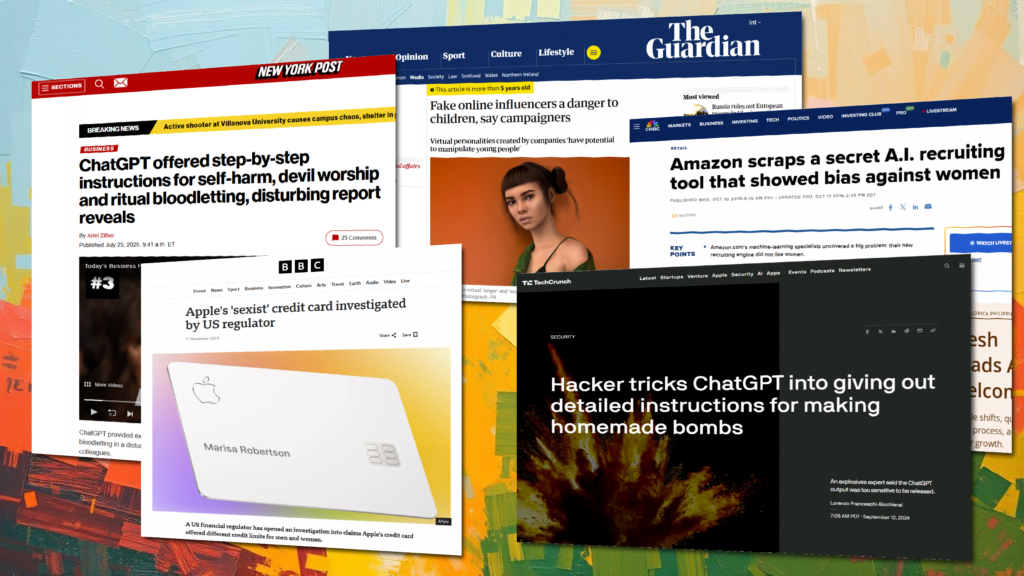
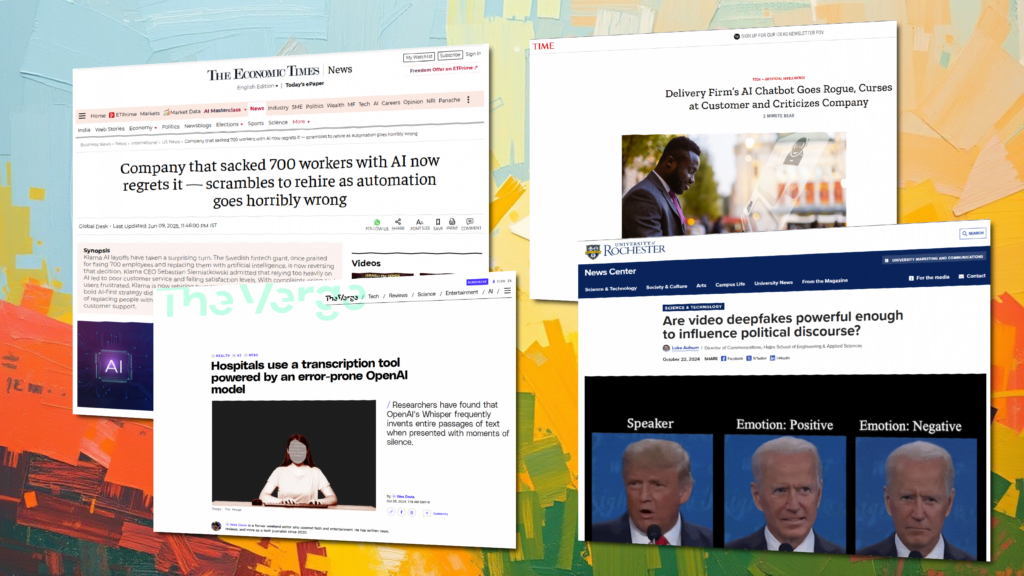
Why generative AI creates new quality challenges Traditional AI trained on structured data often produced outputs that were binary: right or wrong. In generative AI, the boundaries blur. An LLM might summarize a document but omit a key fact, misattribute a quote, or confidently reference a study that doesn’t exist. Real-world incidents highlight the stakes: […]
Why human skills are the secret ingredient in generative AI

Rethinking AI development — from code to human intelligence When most people think of artificial intelligence, they imagine complex algorithms and machine logic. But Sigma is proving that the most powerful AI systems begin with people. The company specializes in training individuals to perform generative AI data annotation — the behind-the-scenes work that fuels model […]
How red teaming AI reveals gaps in global model safety

Red teaming goes global Red teaming — intentionally probing AI models for weaknesses — has long been a key practice in AI safety. But most efforts focus on English, text-based interactions. Sigma AI decided to take things further. In our latest study, they pushed top models to their limits, examining how they behave in different […]