
What is data annotation?
Data annotation is the process of tagging unstructured data such as videos, images, and text to enable machine learning models to identify patterns in this data and generate predictions.
Machine learning models learn from experience, so they need to be trained on accurate, existing knowledge. However, this data must first be attributed, tagged, and labeled to make it easier for ML models to understand it and retain relevant information.
For example, if we want an algorithm to recognize cats in pictures with high accuracy, we would need a variety of labeled images. The dataset should include a variety of cat breeds, poses, lighting conditions, and backgrounds. Additionally, it could also include images without cats (negative examples).
The complexity of the data annotation process can vary based on the different applications and use cases of ML models and AI algorithms. It can be very challenging and time-consuming to acquire, prepare, and label the necessary amount of data — and validate its quality.
Most data annotation projects rely on a combination of human expertise, well-crafted processes, and AI-powered annotation tools.
Why is data annotation important for AI and machine learning?
Data annotation is the key to developing successful machine learning and AI models.
Here’s why:
- Accuracy. High-quality, labeled data provides a clear and consistent foundation for AI models to learn from and contributes to making models more reliable. Inaccurate or insufficient labeling can lead to model biases and errors.
- Improved performance. The more precise and diverse the annotated data, the better an AI model can perform. It can learn complex patterns and make accurate decisions in real-world scenarios.
- Real-world applications. Accurate data annotation unlocks the potential of AI for a wide range of applications, from self-driving cars recognizing objects on the road to medical diagnosis systems analyzing X-rays.
- Establishing ground truth: Data annotation is essential for creating high-quality ground truth data. This data serves as the benchmark for measuring how accurate or effective an AI model is. By meticulously labeling data, annotators provide the “correct answer” that the AI model learns from.
Types of data annotation
Based on the form of your data, there are various data annotation methods. A project might require a combination of these methods depending on its specific characteristics and requirements.
Here’s a breakdown of the main types of data annotation:
- Text annotation
- Audio annotation
- Image annotation
- Video annotation
- Time-series annotation
Text annotation
Text annotation focuses on training machines to understand textual data. A chatbot, for instance, might be trained on specific keywords or intents to identify user requests and provide solutions. If the annotated text is inaccurate, the chatbot might provide irrelevant information. Accurate text annotation is crucial for a smooth user experience.
During text annotation, data points can be assigned to specific sentences and keywords. Here are some common methods used in text annotation:
Semantic annotation
Semantic annotation involves tagging text documents with relevant entities and concepts, such as people, organizations, locations, events, products, or topics. This makes it easier for machines to find and understand information within unstructured data. As a result, computers can not only identify documents but also interpret and read the relationship between the specific parts of metadata and the resources described by semantic annotation.
Through semantic annotation, machine learning models can classify, infer, search, filter, and link information.
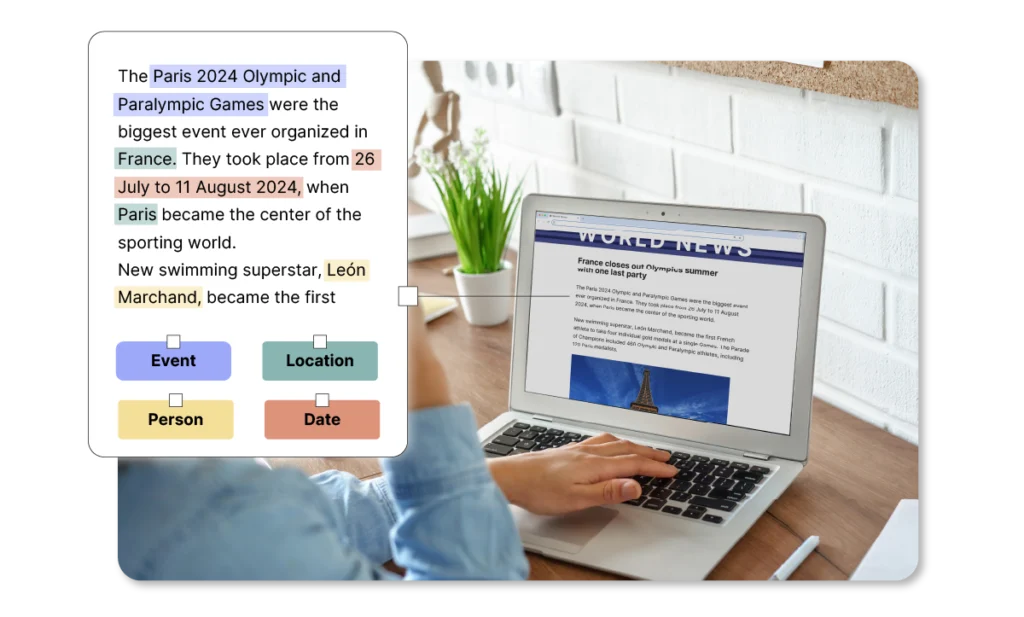
Intent annotation
Here, the focus is on analyzing the underlying intention behind text or search queries. For example, the sentence “I’d like to locate my phone” expresses a request. Intent annotation goes beyond the literal meaning and categorizes the text based on the user’s goal (such as request or approval).
Sentiment annotation
Sentiment annotation consists of tagging the emotions and feelings expressed by text data. That way, machines can learn to recognize human emotions within a text. For example, you could train a machine learning model to analyze customer reviews for a product. Through sentiment annotation, the model can understand the emotions behind the text and categorize reviews as positive, negative, or neutral.
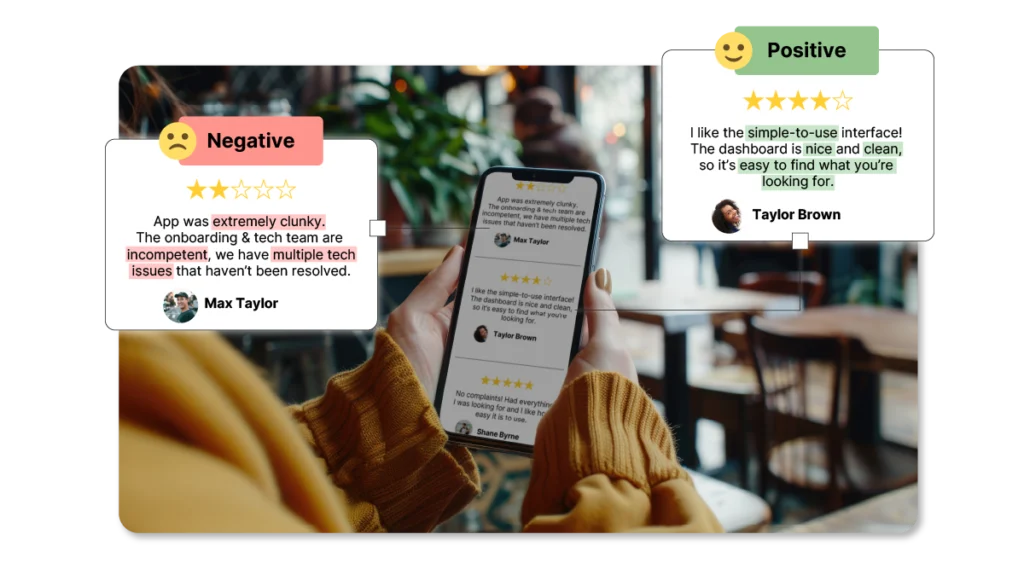
Text categorization
This data labeling process consists of assigning categories to sentences or even entire paragraphs based on their subject matter. This makes it easier for users to find the information they need on a website or within a large document.
Audio annotation
It’s important to distinguish between transcription and annotation. Transcription is the process of converting an audio file word-for-word into text. Annotation, on the other hand, is about labeling and adding additional information (metadata) to an audio file.
The process of audio annotation involves adding labels to an audio file that describe the content of the recording. For example, audio annotation might be used to label the sound of a car horn honking, or a person laughing. By adding these labels, we help machines understand the context and meaning within an audio file.
Image annotation
Image annotation plays a crucial role in training AI and machine learning models. By labeling images with relevant information, we help them develop an understanding of the visual world.
This allows AI models to “learn” by associating labels with images. Depending on the project’s specific needs, the number of labels on an image can vary. These are the most common types of image annotation:
Image classification
Image classification involves training machines with labeled images. The AI model learns to recognize the overall content of an image based on these pre-annotated examples. For instance, an image might be classified as “cat” or “beach” based on the labels it received.
Object detection/recognition
This is a more granular step in image classification, which focuses on identifying and localizing specific objects within an image. Think of it like the difference between labeling a picture as a “forest” and pinpointing all the individual trees within that forest. In image classification, the entire image gets a label. In object detection, each object gets its own label.

Image segmentation
Image segmentation is a more advanced image annotation technique, which involves dividing an image into distinct segments, each representing a separate object. This allows for a more in-depth analysis of the image content. There are three main types of image segmentation:
- Instance segmentation. This allows you to label every individual object in an image, including its location and number within the image.
- Semantic segmentation. This entails labeling similar objects on an image according to properties such as location and size.
- Panoptic segmentation. It combines the detail of instance segmentation with the broader categorization of semantic segmentation.

Video annotation
Video annotation is the process of labeling various aspects within a video to help machines understand its content. While similar to image annotation, video annotation presents a unique challenge – things move! This requires analyzing the video frame-by-frame to ensure subjects/objects are appropriately labeled. Similar to image annotation, tagged information might include details like the size and color of the objects in motion.
Time series annotation
Time series annotation is the process of adding labels or metadata to time series data, such as sensor data. This involves experts identifying and marking specific points, intervals, patterns, or anomalous events within the data that are relevant to a particular analysis or task.
How data annotation works to train machine learning models
Computers are great at crunching numbers, but they often struggle with context. They need to be told what to interpret and be provided with context to make decisions. That’s where data annotation comes in — it bridges the gap between human understanding and machine learning.
Data annotation is a human-led process in which we add labels and context to various content formats like videos, images, and audio. These labels allow machine learning models to recognize content and make predictions based on the labeled data
While the terms “data annotation” and “data labeling” are often used interchangeably, there’s a subtle difference.
- Data annotation is the process of labeling data so machines can understand and learn from it using different algorithms.
- Data labeling, also referred to as data tagging, entails attaching specific meanings (or tags) to individual data points within a dataset. Think of it as identifying single keywords or entities within the data to train machine learning models.
Data annotation for machine learning is vital for creating training data that fuels ML models. The annotated data trains ML algorithms to develop a human-level perception of the world. It equips them with the ability to learn and process new information, leading to more intelligent and human-like behavior. Annotation enables machines to understand and recognize input data and make informed decisions accordingly.
Data is the lifeblood of search, connected devices, customer experience, and commerce, making the need for data annotation even more prominent. A recent report estimates that, by 2025, we’ll generate an average of 463 exabytes of data daily.
Data annotation challenges
Every machine learning and AI project has unique, specific training data needs. That’s one of the reasons why the annotation stage of the AI development process is one of the most complex and time-consuming.
Let’s take a look at some common data annotation challenges:
- Data quality and consistency. For optimal performance, the data used to train a machine learning model needs to be accurate, complete, consistent, and relevant. This involves finding, training, and managing a large team of annotators and developing guidelines to ensure quality and consistency during the annotation process.
- Data quantity and scalability. The sheer volume of data required to train complex models requires efficient data annotation processes that can scale rapidly. For example, this company needed to transcribe speech from 2,000 hours of video material in 24 languages and dialects, with 100% accuracy. Challenging, right?
- Annotation complexity. The different types of data (images, text, audio, video) require different approaches to data annotation. This complexity often demands specialized knowledge and tools. For instance, a robotics company needed to label products within a densely packed image dataset. Achieving pixel-perfect accuracy in such conditions necessitated a dedicated annotation team with specialized skills.
- Subject matter expertise. Many datasets — especially those in specialized fields like medicine, finance, or law — require a deep understanding of the domain to accurately label data. Sourcing annotators with the necessary expertise can be time-consuming and costly. Additionally, ensuring consistency in annotations provided by multiple subject matter experts can be difficult, as different experts may have varying interpretations of data.
- Ensuring ethical and unbiased data. Despite their best intentions, human annotators can introduce biases into datasets, which can be amplified by machine learning models. Ethical AI requires well-documented processes and testing procedures to ensure that datasets are inclusive. Diversity should also be a requirement of any data annotation team. This means working with annotators with various cultural and linguistic backgrounds and broad expertise.
Generative AI creates new annotation challenges
Generative AI is a type of machine learning that uses AI models to create new content. Unlike traditional AI, which is primarily concerned with labeling existing content, generative AI focuses on being able to create (or generate) new content based on a prompt.
Gen AI models are often called large language models (LLMs) because they can understand and generate natural language. They can also be multimodal models, which means they can understand and generate content from multiple modalities, such as text, images, videos, and audio.
Gen AI creates new, unique challenges to data annotation. For example, gen AI models go beyond identifying patterns and making predictions: they can create entirely new concepts and ideas. This makes data annotation for gen AI more complex and demands additional abilities from annotators such as critical thinking, creative writing, subject matter expertise, and reading comprehension.
Data annotation best practices
Successful data annotation lies in the right blend of human expertise, well-crafted processes, and advanced annotation tools.
Following these best practices can help your organization optimize its data annotation process and achieve high-quality data:
- Develop clear data annotation guidelines. Clearly define labels, categories, and expected outputs. Reducing ambiguities ensures consistency among annotators.
- Prioritize data quality. Implement rigorous quality control measures to identify and rectify errors, inconsistencies, or biases in the annotated data.
- Leverage subject matter experts. Involve domain experts to provide accurate and reliable annotations, especially for complex or specialized datasets.
- Mitigate bias. Actively work to identify and reduce biases in the data and annotation process to ensure fairness and equity in the resulting AI models.
- Focus on continuous improvement. Evaluate the annotation and model performance throughout the project to identify areas for improvement and refine annotation guidelines accordingly.
Data annotation services
The growth of machine learning and artificial intelligence models is forcing businesses across all industries to rethink their operations. Data teams need to use clean and accurate data to train ML models.
However, as we’ve seen, data annotation can be complex, time-consuming, and require highly specific expertise. For this reason, you might want to outsource data annotation to expert annotators who can increase your output with a high level of quality and accuracy.
It’s important to note that human-annotated data is often of higher quality and more accurate than machine-annotated data.
With a data annotation service like Sigma AI, you can work with a curated, in-house team of expert annotators, translators, linguists, and subject-matter experts covering more than 500 languages and dialects.
Sigma AI’s process provides multiple checkpoints to ensure quality and accuracy. We assemble each team specifically for your project.
How to get started with data annotation
The first step to get started with data annotation is to define your project goals. This means identifying the problem you need to solve: what do you want to achieve with your AI model? This will give you a clear understanding of the type of data you’ll need to train, whether that’s image, text, audio, or video.
Here’s how we approach data annotation at Sigma AI:
- Project analysis: Our senior team discusses your project details with you and prepares a proposal that meets your needs. You’ll be assigned a project manager based on your needs and their skill set and background.
- Guidelines and requirements: We align on data annotation guidelines, review project requirements, and address objectives and deliverables.
- Tools & procedures setup: Sigma AI’s platform and AI-assisted tools are adapted to your project needs, maximizing throughput and quality. This includes testing and refining the system. If required, we can also integrate with your existing tools.
- Comprehensive test: Annotators generate data using the adapted tools and procedures, including QA. Sigma AI generates a report outlining results and suggestions.
- Client feedback: After we share our findings, we work with you to determine the appropriate course of action. Sometimes we might need to update the guidelines or tune our data annotation tools. Either the guidelines will be updated and tools adapted, or we’ll move into the next phase.
- Annotation/collection at scale: We train the appropriate annotators based on their experience and move into data annotation and collection at scale.
- Quality assessment: We provide data that was prepared using the adapted tools and procedures, including QA. This includes a report on results along with suggestions for improvements to the process or code.
Get better training data for your AI
AI adoption gives your products a competitive edge. Nonetheless, you can only generate value if you use high-quality AI training data. Annotated data is critical for AI and ML projects. The data available in annotated audio, videos, text, or images can help you train the AI and ML algorithms. It’s hard to imagine ML and AI models without sufficient and accurate training data sets.
Sigma AI is the leading data annotation services provider with over 30 years of AI experience. We leverage our extensive expertise to provide human-in-the-loop services powered by technology to millions of projects globally.
The challenge is not just knowing what data annotation is, but how to execute it without common pitfalls. Ensure your project’s success by understanding the roadblocks in 3 training data challenges hurting AI. Then, see the uncompromising technical precision required to power advanced computer vision models in our case study: Pixel-perfect image annotation for product recognition: A case study.
Work with Sigma’s experts to overcome common data pitfalls and deliver production-ready AI performance.