Why linguistic diversity in AI is so important
Conversational AI platforms are steadily becoming essential tools in people’s day-to-day lives. In addition to voice assistants like Siri and Alexa that provide consumers with convenience and time savings, conversational AI enhances work. AI automates processes, analyzes data, streamlines customer service, lays the foundation for new revenue streams, and personalizes customer experiences – if users speak the same language as the platform.
As businesses implement conversational AI solutions to gain a competitive edge, it’s apparent that solutions that only work in limited languages will create haves and have-nots. Linguistic diversity could play a role in tipping the scales toward businesses and enterprises that use cutting-edge NLP tools, denying others the ability to grow and succeed.
Linguistic diversity in AI may also expand opportunities in education and the workplace, allowing more people to communicate with the IT systems organizations use. It can also enable access to healthcare, legal protection, and government services. The impact of excluding people from connecting can be far-reaching. For example, the Australian Social Inclusion Index found that 6.7 million people feel the effects of social exclusion, costing the Australian economy $45 billion each year.
Linguistic diversity in AI can also play a role in creating safe, inclusive workplaces. NLP project teams sensitive to gender and racial biases in speech can avoid designing systems that reflect them. Remember, AI models only know what they learn during training, and biases in language could result in outcomes that marginalize some users. Teams sensitive to this issue can reduce the linguistic inclusion gap in Al/ML.
Linguistic diversity from a use case perspective
As businesses expand globally, they’ll increasingly rely on conversational AI for these use cases. However, in each case, the model’s linguistic diversity, including its ability to communicate with people with different accents or from different cultures will impact performance and bias.
Customer service
All customers using a conversational AI chatbot may not speak the native language of the company’s headquarters. NLP capable of linguistic diversity can allow customers to ask questions in natural language and receive responses that they can easily understand. Furthermore, NLP platforms with linguistic diversity can also save companies labor costs related to hiring employees that can speak various languages.
Negotiations
When people who speak different languages enter into agreements, negotiate, or settle disputes, platforms designed for linguistic diversity can enable each party to access information in their native language.
Media and entertainment
Linguistic diversity in AI can help media and entertainment serve a wider audience and enhance user experiences. Natural language generation (NLG) can enable people to access news or personalize experiences to enjoy a performance in their own language.
Automating business processes
Additionally, as voice assistants become more ubiquitous, they’ll likely expand from the home to the workplace. They can automate internal help desk processes, manage human resources tasks, control audio-visual conference room systems, and access inventory data. Global companies may have employees who speak various languages, and linguistic diversity can allow all users to take advantage of the system.
Addressing linguistic diversity in AI from an ethical perspective
NLP solution builders should also recognize that their skills position them to fulfill a higher purpose. The choices they make can preserve global languages.
The United Nations reports that indigenous languages are disappearing at a rate of about two per month. Sustaining these languages is an important step in acquiring knowledge about, for example, herbal medicines and food processing in different regions of the world.
NLP platform developers can use their skills to document languages so they aren’t lost. For example, a research project from the Rochester Institute of Technology (RIT) aims to preserve the Seneca Indian Nation’s language. Researchers are building automatic speech recognition to document and transcribe the language using deep learning.
Why has natural language processing omitted so many languages?
The lack of linguistic diversity in natural language processing isn’t due to an oversight or a manifestation of bias. There is a fundamental reason: lack of data.
This graph shows an abundance of labeled and unlabeled data for English, Spanish, German, Japanese, and French, the Class 5 languages. Data volumes for Class 4 languages, including Russian, Hungarian, Vietnamese, Dutch, and Korean, are a power of ten less.
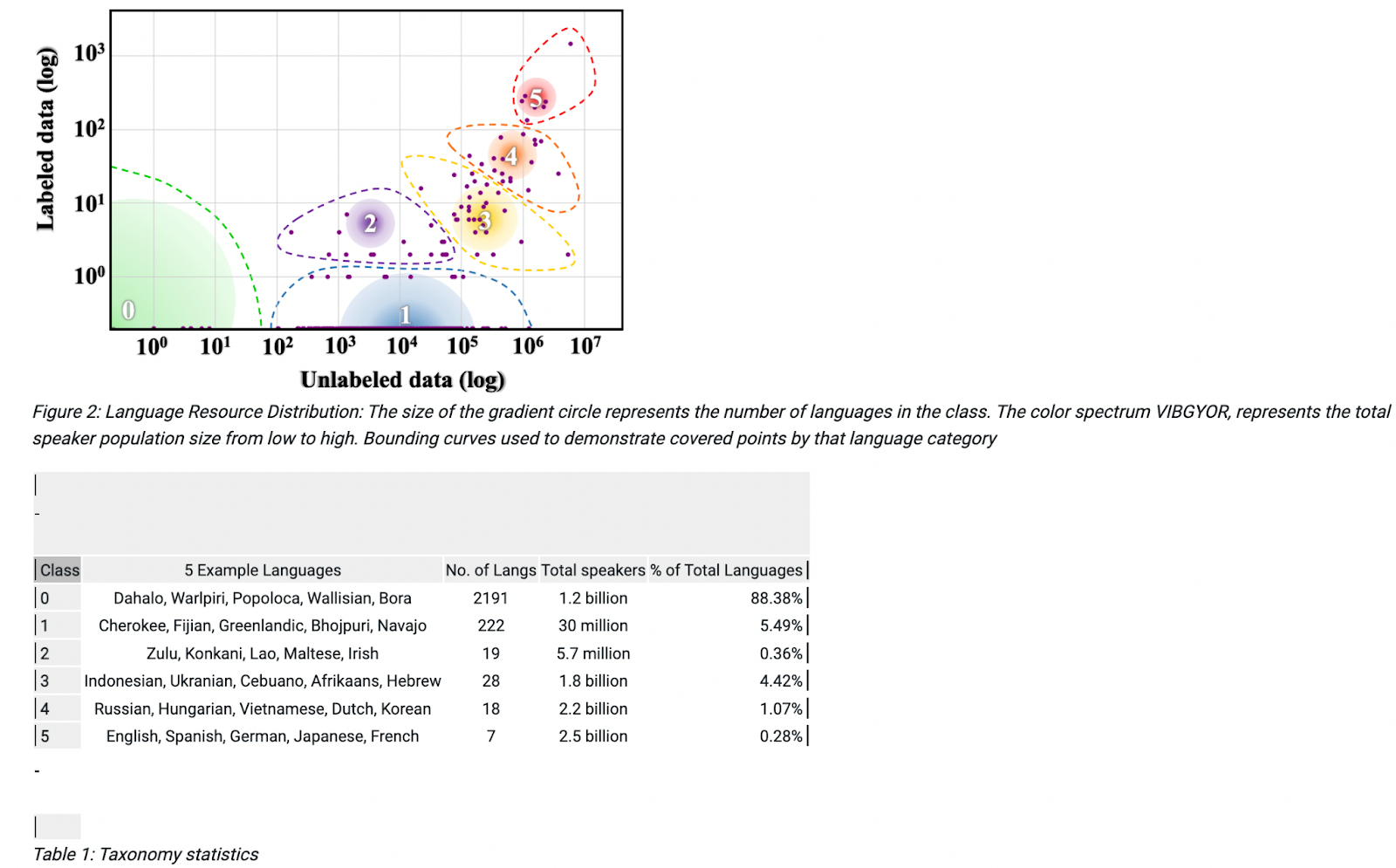
Source: https://deepai.org/publication/the-state-and-fate-of-linguistic-diversity-and-inclusion-in-the-nlp-world
On the other end of the spectrum, very little labeled data is available for Class 1 languages such as Cherokee, Fijian, Greenlandic, Bhojpuri, and Navajo – and virtually none for languages such as Dahalo, Warlpiri, Popoloca, Wallisian, and Bora. Creating a platform that understands and communicates in these languages using standard NLP techniques would require a developer who is a native speaker or a linguistics expert who has studied them.
Solution builders may be able to leverage the work of linguists working to preserve low-resource languages. For example, the Pangloss collection, established in 1995, has created an online sound library with audio or video recordings of 170 languages with about half transcribed and annotated.
Alternatively, NLP project teams could manually collect and annotate data or crowdsource the project to create data sets for each low-resource language. However, this is a time-consuming and costly project, and if crowdsourcing is involved, data quality and annotation consistency may be hard to control.
What does ensuring linguistic inclusion really look like?
A more practical approach than manual data collection of thousands of languages is to build systems that can work in all languages. Recent advances are showing promising results. Some of the techniques that developers are taking to solve some of the problems of linguistic diversity in AI include:
Transfer learning
This technique involves training a deep learning model on one language data set so that it can be used to execute similar tasks on another.
Joint multilingual learning
This method involves training one model on a mixed dataset of multiple languages. It uses word embeddings, representing words in a low-dimensional vector space with words similar in meaning close to each other. The model learns to understand and use words from each language.
Automatic translation
One approach for machine translation begins by training the model to learn word embeddings for every word in each language. The approach also leverages the relationships that words have in every language, such as adjectives used with nouns (e.g., warm and sun or dog and animal). It allows the model to infer a bilingual dictionary and perform translation.
Regardless of the approach solution builders take to create NLP solutions for low-resource languages, the project will collaborate with linguists or academia and community engagement. Each language has its own nuances, requiring insight to develop a platform that works accurately. By building a network of experts and stakeholders, the platform will understand and generate responses that let users know it truly understands their language.
Linguistic diversity has a major impact on all of us
AI is automating and enhancing processes in all areas of life, but this technological advancement is leaving some people behind. Conversational AI interfaces are a natural way for people to interact with machines, but AI/ML models must be trained in the user’s language for them to provide value.
Platform developers must recognize the importance of linguistic diversity in AI, both in addressing the challenge of making NLP solutions available to people who speak low-resource languages and in considering language variations.
NLP teams who build inclusive systems will find they’re more desirable in the market, helping their businesses grow. However, they’ll also find that they’re also leveling the playing field for billions of people, giving them equal access to education, career opportunities, government services, and more.
To effectively train your model, you need diverse, accurate, and consistent datasets. Partnering with Sigma for data collection and annotation services gives you access to a platform that supports more than 300 languages, expertise to decrease or eliminate bias, and a company that is committed to preserving diverse languages.
Language is more than words — it’s context, culture, and connection. Discover how Sigma’s data services and human-centric AI expertise help your platform support true linguistic diversity in every model you build.
Partner with Sigma to bring cultural intelligence and linguistic depth to your AI systems.