The role of data in teaching nuanced AI
Generative AI doesn’t just need labeled data; it needs representative data. That means multilingual, multi-domain corpora designed to teach tone, sentiment, and context — not just keywords.
Sigma’s multilingual, multitask corpus spans over 300,000 human-reviewed texts across 10 languages and seven NLP tasks, from sentiment analysis to named-entity recognition. In one project, our team delivered balanced datasets covering health, banking, and travel domains, enabling a client’s model to use the right vocabulary, regulatory awareness, and tone for each industry.
The importance of representative data is evident across the industry. Advanced Science News highlighted that GPT detectors have mistakenly flagged many submissions from non-native English speakers as AI-generated.
Similarly, Stanford University researchers noted that large models perform well in English but underdeliver in languages such as Vietnamese, and even more so in low-resource ones like Nahuatl. The challenge, as they stressed, is a lack of high-quality multilingual training data.
Why curated data outperforms scraped data
Off-the-shelf datasets often contain bias, irrelevant samples, or incomplete annotations. In contrast, Sigma relies on trained annotators — native speakers and domain experts — to draft, label, and validate every entry. This reduces noise, preserves privacy with built-in anonymization, and accelerates time to market.
The risks of uncurated data are clear:
- Reuters reported on Amazon’s AI recruiting tool, which penalized resumes mentioning “women’s” and downgraded graduates of women’s colleges.
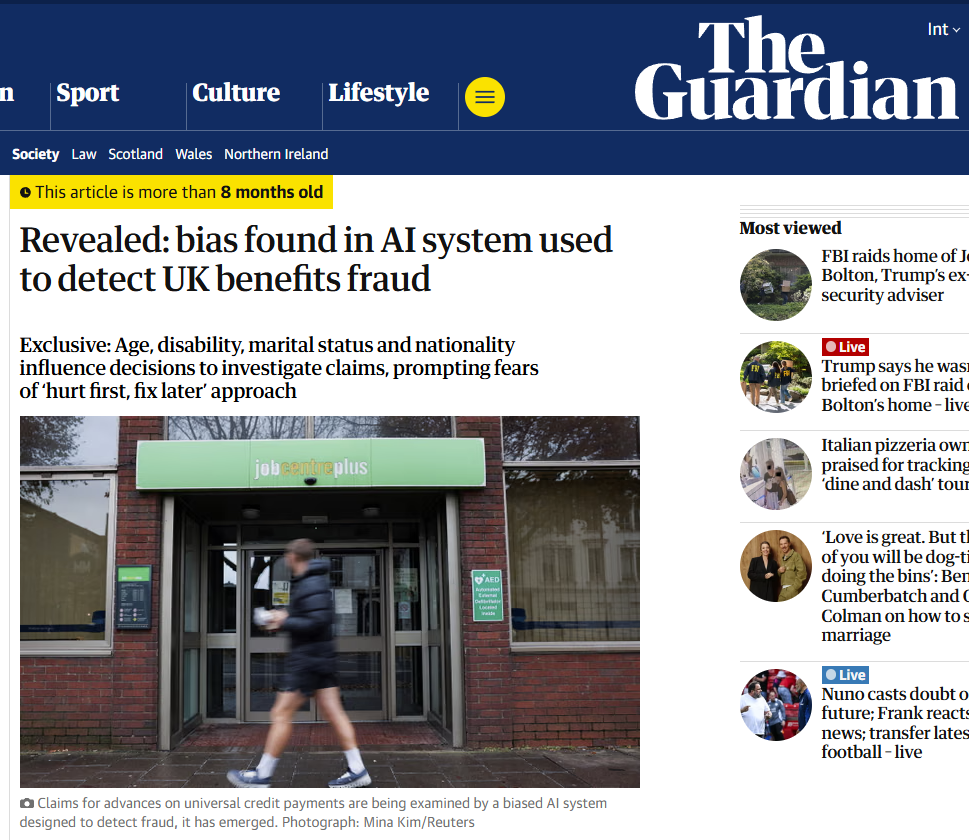
- The Guardian revealed that the UK government’s welfare fraud detection system showed bias based on age, disability, marital status, and nationality.
- Thomson Reuters pointed out that some AI models rely on decades-old datasets, embedding outdated assumptions and creating “feedback loops” that amplify bias, especially against minorities.
Each example demonstrates how flawed training inputs can quickly scale into systemic inequities.
Scaling responsibly with global expertise
AI needs to serve diverse populations. Sigma’s coverage across 700+ languages and dialects enables both scale and specialization, including low-resource languages and niche domains like medical terminology. This helps clients launch AI that resonates worldwide, rather than privileging only high-resource languages.
Industry collaborations reinforce this need. Reuters reported that Veon, Beeline Kazakhstan, the Barcelona Supercomputing Center, and the GSMA have partnered to bridge the “AI language gap,” noting that models too often overlook under-represented languages because of limited online resources.
Avoiding oversimplification and error

Finally, data quality shapes how models interpret complex knowledge. Live Science reported that ChatGPT, Llama, and DeepSeek were nearly five times more likely to oversimplify scientific findings than human experts, and twice as likely to overgeneralize. Only Claude performed consistently across evaluation criteria. These results underscore the importance of curated, domain-specific datasets for reliable outputs in science, healthcare, and enterprise decision-making.
Source better data to deliver better models
Sigma’s approach — human-reviewed, privacy-aware, and balanced across domains — directly addresses the challenges of AI data, ensuring that AI systems perform not just accurately but responsibly.
AI is only as good as the data behind it. Download our free whitepaper, Beyond accuracy: The new standards for quality in human data annotation for gen AI, and see how Sigma’s data expertise fuels the next generation of intelligent systems.